Digital Zettelkasteneering
This post considers some of the issues that come up when trying to port a physical Zettelkasten (PZK) using the OoK+UDC schema into digital form (DZK) on a computer, as well as some use-cases for OoK indexing outside the context of a ZK.
If we take the advice of abramdemski to heart (as noted in Part III of this series), we might decide to implement an electronic form of ZK using insights we have gained from the card-based implementation. There are several observations that come to mind.
In short, it has been pretty tricky doing this. Mostly, the trickiness has stemmed from a tendency to ridiculously over-engineer the structure. I had read in many posts by experienced digital Zettelkasteneers (e.g., Fast 2020) that the way to go was simply foregoing categorisation entirely and just using tags and linking notes (similar to the mini tables of contents described in the previous part). This way, note sequences (folgezettel) would naturally arise. I never felt happy with this and felt that a master list of categories was the “right” way to organise a general collection of notes. After all, Luhmann himself had had two Zettelkästen, the first one of which had possessed some 10 times the number of top-level categories than the second, namely, 108 compared to 11 (Schmidt 2018, p.54). The first one had been for “general” reading, while the second was focused on his more specific theory of society project. So, for someone who was interested in a general categorisation schema, it seemed that a large number of categories was the way to go. Doing so for a physical setup probably does work, as the evangelism of Scott Scheper (2022) reminds us, but I found it hard to translate that idea across to a digital system. As ever, bear in mind that this is simply my (quite likely, inept) attempt, and that your mileage and skill level might differ.
Nomenclature
In what follows, I will use the following nomenclature, based on the degree of depth or ‘nesting’ within the Outline’s tree.
1 Part
11 Division
111 Section
111Z Subject
111Z1 Topic
The two further levels found in the OoK below the Topic level then become Sub-topic (111Z1z) and Sub-sub-topic (111Z1z1) respectively. In earlier posts I did not really draw out this naming system below the Section level, as I was focused (to revisit the disc sector metaphor briefly) on the mechanics of ‘partitioning’ (as it were) the OoK bulk structure onto physical cards. Here, the names used above give a more intuitive mechanism for interacting with the sectoral partitioning of the OoK itself as well as what it seeks to organise.
The Wikipedia page lists the OoK down to the Section level (i.e., 3 digits, 111), which is sufficient for an initial and cursory overview. However, if one consults a list which also includes the Subject level (i.e., 3 digits and a capital letter, 111Z), then an entirely new understanding and appreciation of the OoK emerges. One is then able to see the broad sweep of knowledge laid out in the series of Subjects – which are more likely to be familiar from general reading – that seamlessly ‘blend’ into each other as we move through the numbering (which, as noted in earlier posts, broadly follows the cosmic evolution time-line), and which provides a much more powerful set of ‘hooks’ to ‘situate’ new knowledge as we interact with it. If there were a fourth column on the Wikipedia page that listed the Subjects, then this progression would be immediately and obviously clear. For many purposes, if not perhaps most, the Subject (or perhaps the Topic) level will be quite sufficient for indexing the classmark (or sector) of a new piece of knowledge. Sometimes one might need to go a bit deeper, but this has not been as common as I had initially thought.
Digital forms
A digital ZK
The initial advice from abramdemski might suggest, at first glance, that a directory structure be constructed that mirrors the multilevel structure of the card-based OoK. That is, 10 top-level Parts, numbered 0-9, with each Part containing Divisions, each Division containing Sections, the Sections with Subjects, and the Subjects with their respective Topics and sub-topics and so on. If the directory names are confined to being just the number or letter for that level in the OoK, then the so-called ‘breadcrumb’ view of the directory structure will show the complete OoK address. Sounds like it could be pretty efficient.
However, understanding this view would require an extremely high degree of familiarity with the OoK, or at least a copy of it to be always at hand. If the directories have both number and caption included, then this would make navigating the tree structure that much easier. But, the captions make the folder names quite long and unwieldy, which makes it difficult to read these on the screen. Also, this ‘simpler’ directory-based sectioning structure does not address the difficulty of ‘proximity inspection’ across sections/directories, even as it reduces that issue to zero within a section/directory. And it still requires us to address the problem of naming files within directories.
Another tack, therefore, might be to create a single flat directory structure that will house all of the digital ‘cards’, both the ‘structure’ cards as well as the ‘content’ cards (i.e., what were the coloured and plain white cards, respectively, from the earlier discussion). The use of physical cards in an analogue ZK allows for a total freedom from ‘lock-in’ to any particular card vendor, since cards of the same size are, as it were, completely inter-operable, irrespective of the vendor from whom they were acquired. The digital equivalent of this inter-operability and freedom from lock-in is the use of plain text files utilising Markdown for formatting, since these combine portability as well as avoidance of any vendor lock-in to any particular software package, since Markdown is just a basic plain text file. Many of the software-based Zettelkästen I have seen are designed this way.
The naming of files with prefixes derived exactly from the OoK will not necessarily produce a listing of files such that zettels which would be adjacent to each other in the physical card-box remain adjacent in the file list. However, done carefully, in the case of a DZK with OoK-style numbering in a single flat directory, the ability to do ‘proximity inspection’ can be largely carried over. That is, we can more-or-less look around at ‘nearby’ zettels in the file listing in the much the same way as we can look at nearby zettels in the card-box. But it requires some careful thinking about the file naming convention used.
This artefact of computer filing systems requires us to modify the identifiers for the main subdivisions in certain ways, depending on the software chosen. We cannot simply use ‘2’ for Earth, as we can in the physical box, since this would not list correctly alongside the hundreds or thousands of other files. Instead, we need to use trailing zeroes for classmarks that are not at least 3 digits long, or some other trick in one or two cases. So, for example, Part ‘0’ – The Branches of Knowledge – had to have the filename beginning with ‘-0’, in order to sort properly, since 000 did not, while 00 – Prolegomena and 001 – Science & knowledge in general ... did sort properly. Similarly, 13 – The Universe, had to become 130, and so on. This is slightly inconvenient, but it at least has the same 3-digit primary format as the more-familiar Dewey decimal system, so this was only a minor wrinkle. In this way, using trailing zeroes for the Parts and Divisions leads to a more or less correct rendering of the order of the Part, Division, Section and Subject files within the File Explorer sidebar window of, for example, Obsidian, a very popular note-taking program available on multiple platforms (see later).
Notwithstanding the comment at the top of the previous post about the much higher degree of structuring found in the UDC compared to the OoK, the UDC—whose very powerful ability for specification using auxiliary notation was demonstrated in Part IV—may well be better suited to an electronically-implemented classification schema in a knowledge-base system, not necessarily for a DZK, although the OoK would still be a very useful format for organising knowledge in a DZK using some sort of information field to hold the classmarks (see below).
The UDC, by design, was intended to serve as a way to “create a comprehensive listing” on physical index cards “of everything that had been written since the invention of printing” (McIlwaine 2007, 1). McIlwaine tells us, in a footnote on page 1 of her book, that a Dutch television program in 1998, “Alle kennis van de Wereld” [All the world’s knowledge], “portrayed this very clearly and demonstrates the vast scale of the enterprise” (ibid.). And it is an amusing reminder once again of how this whole series of posts began: as an attempt to find a way to organise ‘the sum total of all human knowledge’, which was the very purpose for which the UDC was designed to be used.
So, although the numbering system of the UDC does not closely reflect the sequence of the cosmic evolutionary timeline, as was noted in Part III, it nonetheless would serve as an excellent classification system for those Zettelkasteneers for whom the timeline’s sequence is not a major design consideration, and for whom a very high degree of quite detailed granularity is required. Specifically, the use of the UDC auxiliary notations allows for very highly targeted string searches in computerised implementations, but a flat single-directory structure of Markdown files could almost certainly not be used to house the entire DZK based on UDC classmarks. The reason is that the various auxiliary symbols would very likely not be allowable in the filenames; the slash character “/” is the archetypal case in point. In the end, it was an unbelievably cumbersome task to try to create the ZK as a file structure in a single directory, even based just on OoK classmarks. However, it turned out to be useful in other ways to create just the structure of the OoK itself without the content zettels that would go into it. In other words, the electronic equivalent of just the (coloured) structure cards turned out to be useful even without any of the file equivalents of the (white) zettel cards themselves being present (see later).
Indexing references in Zotero
This system of indexing is quite useful even apart from any usage pertaining to the mechanics of a ZK, as noted above. For example, I have written before of using Zotero as my bibliographic reference manager. There are currently (after a fairly significant purge following my recent retirement from full-time formal academia) some 7100-odd reference items contained within my main Zotero library. These range from books to book chapters to journal articles to conference papers, as one might expect, but also to web pages, blog posts and online multimedia. With these latter items, Zotero is able to ‘ingest’ these pages and store a local ‘snapshot’ of them, which is very handy indeed for reference purposes, especially as websites and blog posts tend to be somewhat ‘volatile’ and quite often transient. With a stored snapshot, one does not need to worry that a URL might eventually become ‘404 dead’ – the item as it was will still exist within the Zotero file structure itself and remains available for viewing, even after the original may have vanished entirely from the web.
In Zotero, there are over three-dozen or so item types for references: books, book chapters, journal articles, conference papers, and so on. Each item type utilises several information fields to hold relevant information about the item: titles, author names, dates, publishers, places, and so on. But there are also other types of information field that are less tied to the source itself and have more to do with related information, such as Call Number, or the date the item was added to the reference collection, or the Archive housing the source, and so on. There are in total some three-dozen or so of these information fields that may or may not be part of an item type. For example, there is no Call Number field for Web Page or Blog Post (which makes sense, since call numbers were invented for shelving physical objects, usually books). There are, in fact, only two fields that are present for each and every Item type: the Extra field, which is used to add reference information that might not have a specific field available, and (since version 8.0) the Licence field, which is meant to contain information about the copyright terms or status of an item (it was called Rights before the new name). In recent years, when grabbing a snapshot of a web page on a publisher’s site, you will often find this field filled in, most often with a URL to the publisher’s policy page.
The Licence field cannot be used for citations. It therefore seems to be well suited to function as an ‘internal’ field that one can access and view as a column in the main window of Zotero, provided one does not care about not having a link to the licensing conditions. In my early attempts, I added this column, then called Rights, to the very left-hand side of the main view, followed by Author/Creator, Year, Notes, Attachments, Title, Item Type, Publication, Date Added, Call Number and Citation Key (generated by the BetterBibTeX plugin). The Licence field, along with the Year, Author, Title, etc can be used to sort the items visible in the main view window. I therefore initially used this field to hold an OoK index classmark for the given reference item. When this column is sorted, items that are ‘near’ each other in the OoK are brought into closer proximity in the main view of Zotero. Thus, the use of the OoK+UDC classmark is another way of indexing reference items.
For example, when I first started writing this post quite some time ago, I had a quick look to see what had been indexed so far (I was very far from completing this, as it is a very big job! Only ~900 or so of the total were indexed, although, frankly, I had not pursued this anywhere near systematically). Near the top of the OoK-numerically sorted list, just following the various items dealing with Zettelkasteneering (001H and sub-sections, as noted in earlier posts), I noticed that there were six items indexed with 001J4 which, if you look back through the earlier posts in this series, you will recall is a classmark introduced from UDC – Reported phenomena not yet fully explained eg, UFOs, crop circles, Loch Ness monster (Allen 2021; Cook 2023; David 2023; Gorvett 2023; Hynek 1974; Sagan and Page 1972). The next item shown in the window had classmark 001J5 which is Deliberate scientific hoaxes & frauds and is the very famous hoax by Alan Sokal which was a load-of-utter-rubbish paper he had managed to get published in a post-modern journal (Sokal 1996b). Highlighting this item and then sorting on Author/Creator showed an additional as-yet un-indexed item also by Sokal which discusses the hoax itself (Sokal 1996a).
The classmark can also have UDC-style auxiliaries built out of the OoK designators. For example, the paper:
Schulte P, et al. The Chicxulub asteroid impact and mass extinction at the Cretaceous-Paleogene boundary. Science. 2010 Mar 5;327(5970):1214–8. doi:10.1126/science.1177265
discusses the asteroid impact that caused the mass extinction event at the end of the Cretaceous Period. The primary OoK classmarks for this are 232B2 which has to do with extraterrestrial impacts, and 242B3 which has to do with extinctions in the fossil record. These together form the first part of the classmark. Next, the specific extinction mentioned is the ‘end-Cretaceous’ extinction event, which in the geologic record forms the boundary between the Cretaceous (243C3) and Paleogene (243D1) Periods, which could therefore be connected by the UDC connection symbol, “+”, whence the classmark 243C3+D1, where the leading 243 in the second part of classmark is understood by common abbreviated usage. However, since these two time periods are immediately adjacent to each other anyway, we could also use the extension auxiliary, the slash character, “/”, which joins the two classmarks together, and seems to better connote the ‘boundary property’ between them. Whence the full classmark is then
232B2:242B3:243C3/D1
which can then be read off as, something like: “extraterrestrial impact, mass extinction event, K-Pg boundary”. This then also provides a potential set of keywords. However, while there is no use of the double quotes to indicate times (as shown, e.g., in Part IV), it is not really necessary, since the classmark itself already denotes the time period.
I had in the past attempted to used ‘tags’ for classifying items in Zotero, like many Zettelkasteneers suggest to do for the entries in their DZK, but this system always seemed to grow unwieldy and suffered from the problem of increasingly inconsistent tagging as time went on. In the end, I just deleted all tags. The idea was to start afresh using the OoK-ish classmarks, such as just demonstrated above. That process continued for a surprisingly (in retrospect) long time, but there eventually came a point when I came to feel that even that, too, if it was ever completed, would not be entirely satisfactory, owing to the amount of time needed to maintain the structure. It gradually started to feel like I was spending far more time filing items than actually using them for research. This really came to a head while I was researching and writing the paper for NATO on the future of the rules-based international order. So, in the end, I deleted even these, as the initial enthusiasm and, frankly, optimism, for completely indexing all reference items with OoK classmarks gradually wore off in the cold, hard light of daily use; each new item required a bit of digging to find its place, and introduced some friction into the process which only ever seemed to increase over time. Eventually, that friction wore me down. Now I just use the Collections feature to group items into broad topics and/or specific projects, and do string searches on Title, Author, etc, or on everything, including attached files. It usually gets me where I was wanting to go, and is much less cumbersome.
Electronic OoK
It was while trying to set up this OoK-ish classmark structure in the Licence field of Zotero that I had also started to build up the OoK as a set of files in a dedicated computer directory, using the expanding windows view found in Obsidian. As noted, I gave up on the creation of any actual content zettels pretty quickly, but it occurred to me that the bare structure, absent content, might be quite useful in and of itself. In Obsidian, it is possible to ‘hover’ the cursor on a link and have a small window expand or ‘pop out’ of the view. This can then be navigated in a similar way, again popping out another window, and so on, to several such overlain windows. The idea now was to have an electronic way to quickly look up a classmark, rather than thumb through an increasingly-worn hardcopy such as I described in earlier posts, in order to know how to classify an entry in Zotero. Thus, one simply navigates via the live links to find the appropriate classmark for any new addition, which is much quicker. A screenshot of this is shown here in Figure 1 for the chain that leads to 131D2 - The general theory of relativity by way of the cross-reference found in 131B - Gravitation:
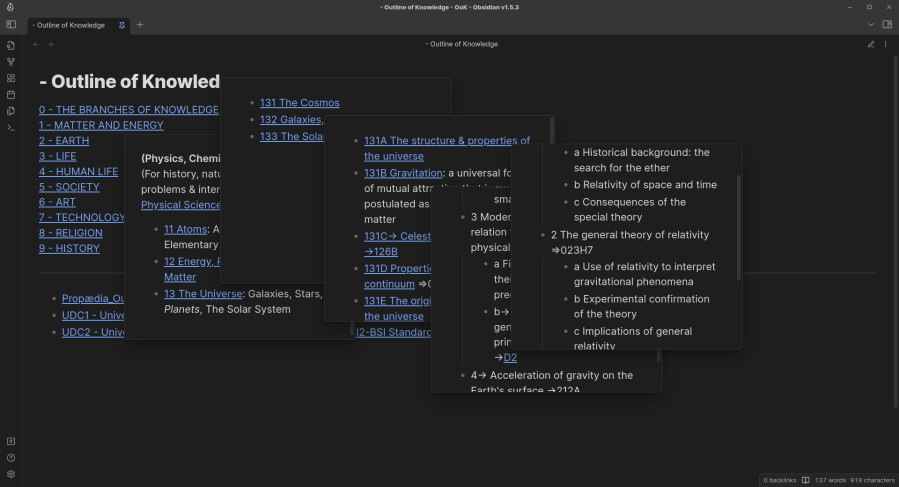
The key structural point here was to create the OoK only down to the Subject (111Z) level as distinct files. Then, within each of these files, to fill in the Topic, sub-topic and sub-sub-topic structures, to the extent that they are present. The reason for this is that, for some Subjects, there is nothing beyond the mere name, so this was the furthest level down one could take the file structure before introducing gaps. It was also, as noted at the top of this post, the most intuitive way to view the files in the file explorer, such as is shown here in Figure 2:
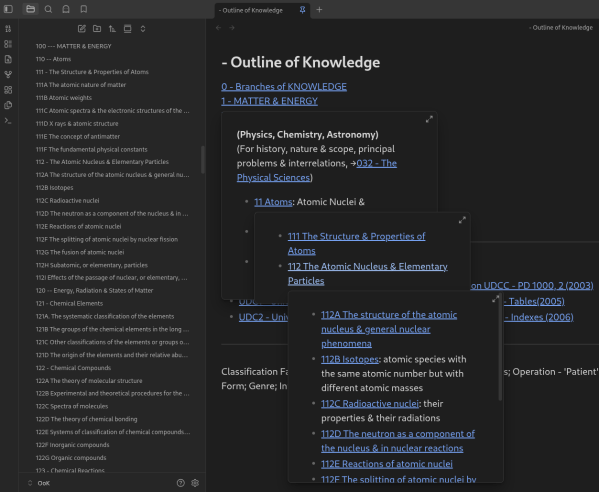
In this approach, the files leading down to the 111Z level are just collections of links to the next level down, as is evident from the 1 - MATTER & ENERGY link expanding into the 11 Atoms, and 112 The Atomic Nucleus & Elementary Particles links. The actual files are 100 --- MATTER & ENERGY, 110 -- Atoms, and 112 - The Atomic Nucleus & Elementary Particles. The visible naming in the expanded view is deliberately different compared to the actual naming of the files required to get the file ordering right, which also uses capitals and dashes to set these major structure files apart in the file view (a throwback to when I tried to include content files as well). This approach is used in the file system as shown on the left side of the image, which is formatted in Markdown to produce the more OoK-ish name view shown on the right. An example of the sub-structure of Topics etc placed into the 111Z files as can be seen in Figure 1. The daily-use OoK navigation view was as shown in Figure 1, hiding the explicit filename structure. This setup made it much quicker and easier than using a hardcopy book to look up classmarks for filing items into Zotero, but, as noted above, even this much quicker route ended up taking up more time that I was willing to devote to it.
Reflections
In the end I gave up on both the card-based Zettelkasten as well as the electronic form of using the OoK classmark in Zotero. The OoK in an electronic form still exists on my computer, with Obsidian as the program used to view and traverse it. But I no longer consult it because I essentially no longer use the OoK classmarks at all, except for a bit of fun now and then to ‘tour through’ the OoK. The next (and final) post in this series will reflect on the lessons learned from this multi-year attempt to go “full Zettelkasten” on my research process. I doubt it will be an overly-long post…
References
Allen, Nick. 2021. “The Pentagon Thinks UFOs May Exist After All… And the Evidence Is Growing.” The Telegraph, May 21. https://www.telegraph.co.uk/news/2021/05/21/ufo-uap-aliens-report-sightings-us-government-encounters-barack/.
Cook, Ellie. 2023. “Congressman Says Alien UFO Tech Is Being ‘Reverse Engineered’ in Secret.” Newsweek, March 7. https://www.newsweek.com/congressman-tim-burchett-ufo-technology-reverse-engineered-1786068.
David, Leonard. 2023. “The US Congress Is Holding UFO Hearings This Week. What Might We Learn?” Space.com, July 24. https://www.space.com/ufo-uap-full-disclosure-congressional-hearings.
Fast, Sascha. 2020. “Introduction to the Zettelkasten Method.” Zettelkasten Method, October 27. https://zettelkasten.de/introduction/.
Gorvett, Zaria. 2023. “The UFO Reports Piquing Nasa’s Interest.” BBC Future, July 26. https://www.bbc.com/future/article/20230726-the-weird-incidents-piquing-nasas-interest.
Hynek, J. Allen. 1974. The UFO Experience: A Scientific Inquiry. Corgi Books.
McIlwaine, Ia C. 2007. The Universal Decimal Classification: A Guide to Its Use. Revised. UDC Consortium. https://www.worldcat.org/title/universal-decimal-classification-a-guide-to-its-use/oclc/443808175.
Sagan, Carl, and Thornton Page, eds. 1972. UFO’s—A Scientific Debate. W.W. Norton & Co.
Scheper, Scott P. 2022. “How to Get Started Building an Antinet Zettelkasten.” The Website of Scott P. Scheper. https://scottscheper.com/letter/1/.
Schmidt, Johannes F. K. 2018. “Niklas Luhmann’s Card Index: The Fabrication of Serendipity.” Sociologica 12 (1): 53–60. https://doi.org/10.6092/issn.1971-8853/8350.
Sokal, Alan. 1996a. “A Physicist Experiments with Cultural Studies.” Lingua Franca 6 (4): 62–64. http://linguafranca.mirror.theinfo.org/9605/sokal.html.
Sokal, Alan. 1996b. “Transgressing the Boundaries: Toward a Transformative Hermeneutics of Quantum Gravity.” Social Text, Science Wars, no. 46/47 (Summer): 217–52.
